|
I got my Ph.D. in Computer Science at USC, advised by Prof. Hao Li and Prof. Randall Hill, Jr. I also worked in the Vision and Graphics Lab at USC Institute for Creative Technologies. In summer and fall 2020, I was a research intern at the Facebook Reality Labs (Reality Labs, Meta), hosted by Zhaoyang Lv. In summer 2018, I was a research intern at Snap Inc., working with Chongyang Ma and Linjie Luo. From fall 2016 to spring 2017, I visited the Max Planck Institute for Intelligent Systems (Tübingen), working with Timo Bolkart, Javier Romero, and Michael J. Black. I did my B.Eng. at Xidian University and M.Sc. (with honor) at USC, both in Electrical Engineering, during which I had worked in Agilent Technologies (Keysight) and Dolby Laboratories. |

Email: first_name dot last_name at protonmail dot com |
|
My research interests are computer vision and computer graphics. Most of my work aims to capturing, modeling and understanding our dynamic 3D world. This involves analyzing the geometry, motion and appearance for dynamic humans, objects and scenes. |

|
Gwanghyun Kim, Xueting Li, Ye Yuan, Koki Nagano, Tianye Li, Jan Kautz, Se Young Chun, Umar Iqbal ICCV 2025 paper / arxiv / project page / bibtex GeoMan produces accurate and temporally stable geometric predictions (depth and normal) for human videos. The root-relative depth representation preserves human scale information, enabling metric depth estimation and 3D reconstruction. |

|
Zhengming Yu, Tianye Li, Jingxiang Sun, Omer Shapira, Seonwook Park, Michael Stengel, Matthew Chan, Xin Li, Wenping Wang, Koki Nagano, Shalini De Mello SIGGRAPH 2025 (Conference Track) paper / project page / bibtex GAIA generates animation-ready Gaussian avatars by learning only on in-the-wild image datasets. GAIA supports photorealistic novel view synthesis, individual control of identity and expression, and interactive animation and editing. GAIA is featured in the Emerging Technologies demo at SIGGRAPH 25. |

|
Shengze Wang, Jiefeng Li, Tianye Li, Ye Yuan, Henry Fuchs, Koki Nagano, Shalini De Mello, Michael Stengel CVPR 2025 paper / arxiv / project page / bibtex BLADE is a human mesh recovery method that accurately recovers perspective parameters from a single image. BLADE outperforms existing methods at estimating subject depth, focal parameters, 3D pose, and 2D alignment. |

|
Sharath Girish, Tianye Li*, Amrita Mazumdar*, Abhinav Shrivatava, David Luebke, Shalini De Mello NeurIPS 2024 paper / arxiv / code / demo / project page / poster / bibtex We develop efficient representations for streamable free-viewpoint videos with dynamic Gaussians. QUEEN is able to capture dynamic scenes at high visual quality and reduce the model size to just 0.7 MB per frame while training in under 5 sec and rendering at ∼350 FPS. QUEEN is featured at GTC 2025 (San Jose and Paris) and SIGGRAPH 2025. |
|
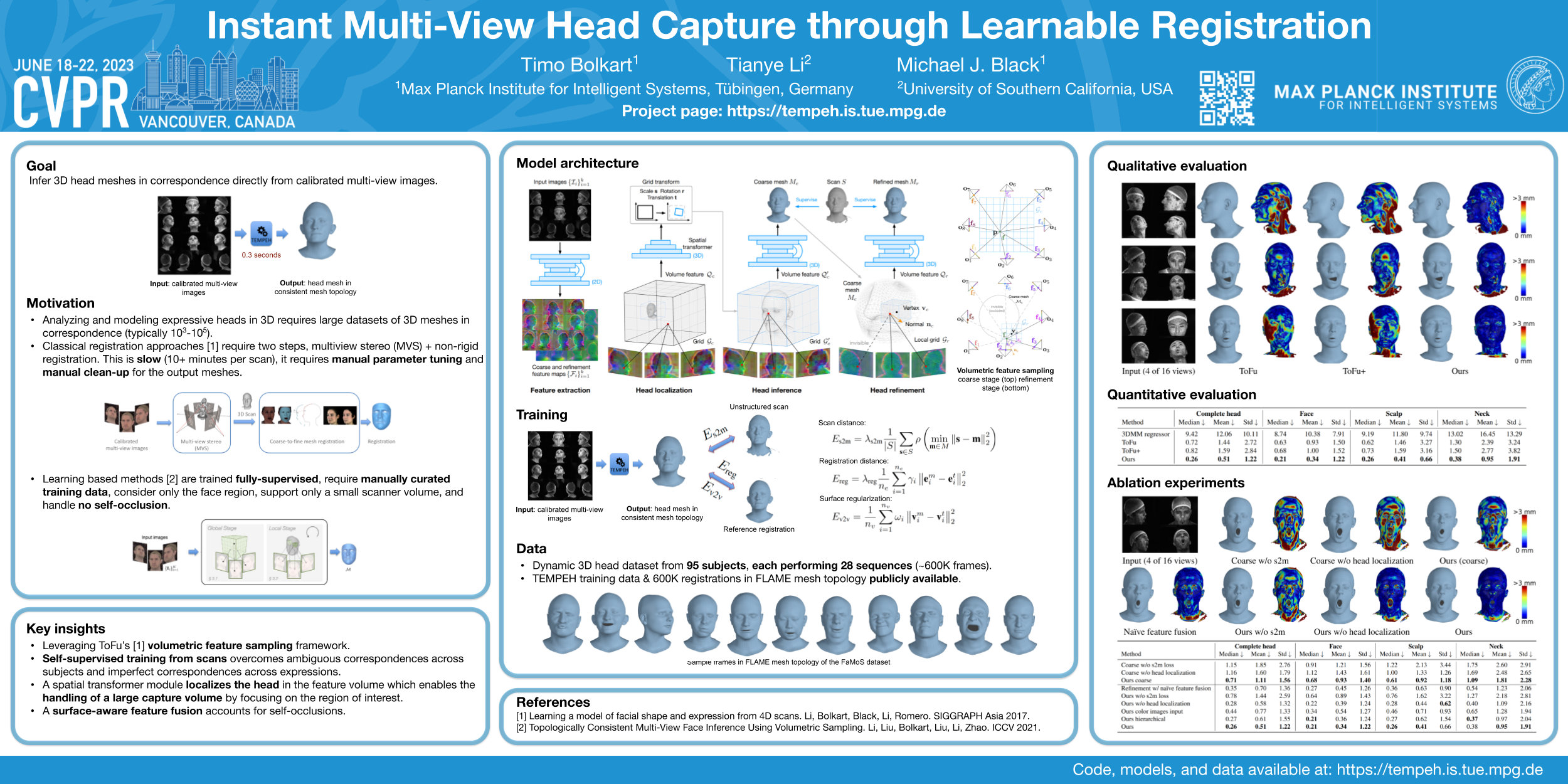
Timo Bolkart, Tianye Li, Michael J. Black CVPR 2023 paper / arxiv / code / project page / video / supplemental / data / poster / bibtex TEMPEH reconstructs 3D heads in dense semantic correspondence directly from calibrated multi-view images. It is one step beyond ToFu, as it uses self-supervised training from scans to resolve ambiguous and imperfect dense correspondences, with head localization in a large capture volume and occlusion-aware feature fusion. |

|
Tianye Li*, Mira Slavcheva*, Michael Zollhoefer, Simon Green, Christoph Lassner, Changil Kim, Tanner Schmidt, Steven Lovegrove, Michael Goesele, Richard Newcombe, Zhaoyang Lv CVPR 2022 (Oral Presentation) paper / arxiv / project page / video / supplemental / data / poster / bibtex We propose a novel and compact dynamic neural radiance field (DyNeRF) that captures complex dynamic scenes and enables photorealistic 3D video synthesis from wide view angles and at arbitary times. We also present the neural 3D video synthesis dataset. |

|
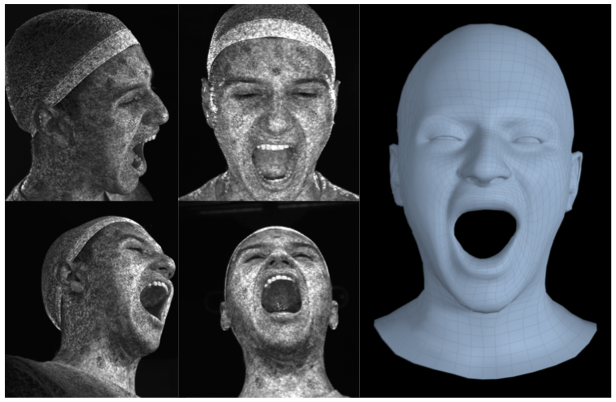
Tianye Li, Shichen Liu, Timo Bolkart, Jiayi Liu, Hao Li, Yajie Zhao ICCV 2021 (Oral Presentation) paper / arxiv / code / project page / supplemental / video / talk / slides / poster / bibtex We propose the ToFu framework that uses volumetric sampling to predict accurate base meshes in consistent topology directly from multi-view image inputs in only 0.385 seconds. ToFu also infers high-resolution skin appearance and detail maps, which enables photorealistic rendering. |

|
Shichen Liu, Tianye Li, Weikai Chen, Hao Li TPAMI 2020 paper / bibtex An extended version of the Soft Rasterizer. |
|
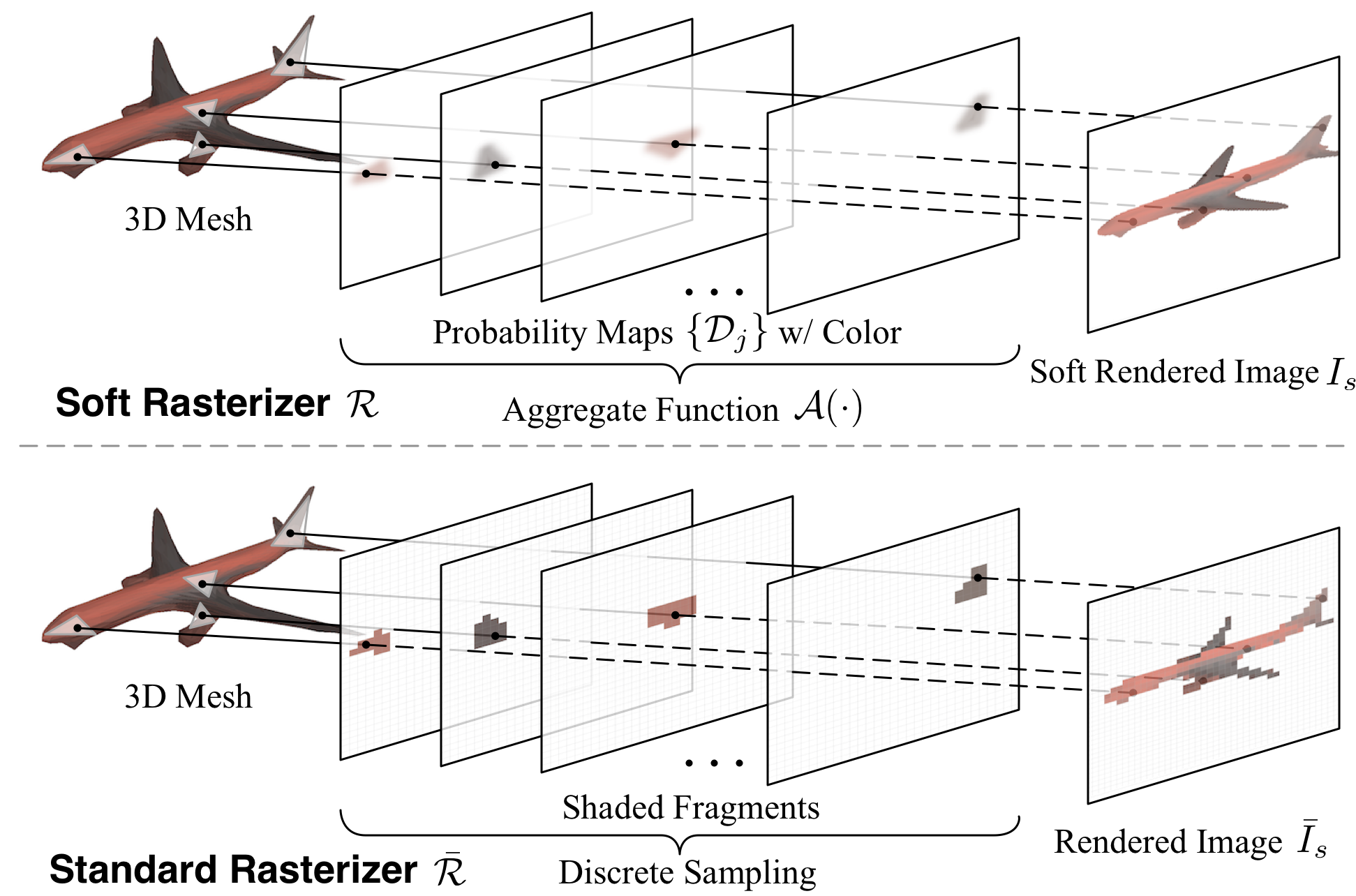
Shichen Liu, Tianye Li, Weikai Chen, Hao Li ICCV 2019 (Oral Presentation) paper / code / poster / bibtex A rasterization-based differentiable renderer for 3D meshes, Soft Rasterizer (SoftRas), that supports reasoning for geometry, texture, lighting conditions and camera poses with 2D images. An extended version of SoftRas has been incorporated into the PyTorch3D library. |

|
Yajie Zhao, Zeng Huang, Tianye Li, Weikai Chen, Chloe LeGendre, Xinglei Ren, Jun Xing, Ari Shapiro, Hao Li ICCV 2019 (Oral Presentation) paper / project page / bibtex Given a face portrait, this system corrects the perspective distortion, easing subsequent facial recognition and reconstruction and reducing the bias for human perception. |

|
Zeng Huang, Tianye Li, Weikai Chen, Yajie Zhao, Jun Xing, Chloe LeGendre, Linjie Luo, Chongyang Ma, Hao Li ECCV 2018 paper / supplemental / video / poster / bibtex Utilizing a learnt implicit representation for geometry, the method is able to capture dynamic performances of human actors with very sparse camera settings (3 or 4 views), which enables to high-quality volumetric videos. |
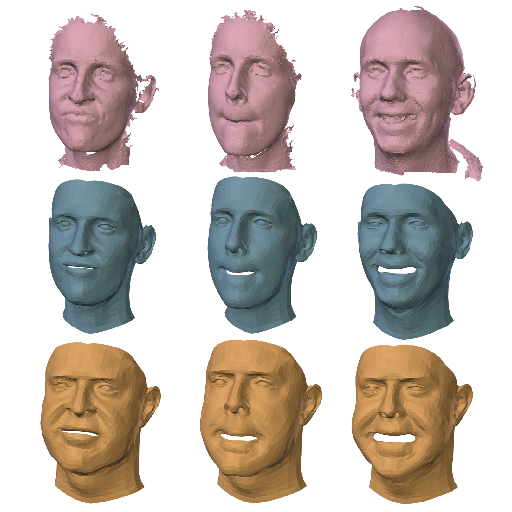
|
Tianye Li*, Timo Bolkart*, Michael J. Black, Hao Li, Javier Romero SIGGRAPH Asia 2017 / ACM Transactions on Graphics (TOG) paper / supplemental / video / project page / model & data / bibtex We propose a light-weight yet expressive generic face model, FLAME, by learning from large high-quality datasets and an appropriate separation of identity, expression and pose. The FLAME model has been incorporated into the SMPL-X model. |

|
Shunsuke Saito, Tianye Li, Hao Li ECCV 2016 paper / supplemental / arxiv / video / poster / data / bibtex A real-time facial performance capture system from single RGB camera, that is robust to occlusion, thanks to an effective and real-time facial segmentation network. |
{kind=link}
|
|

|
Jonghyun Kim, Michael Stengel, Amrita Mazumdar, Tianye Li, Cheng Sun, David Luebke, Shalini De Mello SIGGRAPH Asia 2025 - Emerging Technologies project page / bibtex Play4D unlocks efficient dynamic 4D neural scene reconstruction for Physical AI testing in Isaac Sim, along with the compressed streaming and free viewpoint immersive viewing on VR and light field displays. |

|
Amrita Mazumdar*, Tianye Li*, Michael Stengel, Jonghyun Kim, Shalini De Mello with Wil Braithwaite, Cheng Sun, Seonwook Park GTC 2025 (San Jose & Paris) and SIGGRAPH 2025 project page / bibtex We present novel immersive 3D experiences that allows users to move around in a streaming volumetric video, in 3D, in real-time. This allows for a highly immersive video viewing experience, especially when paired with 3D displays such as light field display or virtual/mixed reality headsets. |
|
|
 |
Organizer:
CVPR 2025 Tutorial on Volumetric Video in the Real World CVPR 2025 Workshop on Photorealistic 3D Head Avatars (P3HA) Reviewer: CVPR (2020-2025), ICCV (2019-2025), ECCV (2020-2024), SIGGRAPH (2022, 2024, 2025), SIGGRAPH Asia (2022-2025), TPAMI (2021-2025), IJCV (2020), CVIU (2024), NeurIPS (2020, 2024, 2025), AAAI (2020), VRST (2020), Eurographics (2019), Pacific Graphics (2018), CAVW (2018), ICCV Workshop PeopleCap (2017), IEEE VR (2017) Outstanding Reviewer, CVPR 2020 Outstanding Reviewer, CVPR 2021 Outstanding Reviewer, ICCV 2021 Top Reviewer, NeurIPS 2025 |
|
|
Teaching:
Teaching Assistant, CSCI 576 Multimedia Systems Design, Fall 2021 Teaching Assistant, CSCI 677 Advanced Computer Vision , Fall 2019 Teaching Assistant, CSCI 621 Digital Geometry Processing, Spring 2018 Grader, EE 559 Mathematical Pattern Recognition, Spring 2015 |
|
Latest update: December 17, 2025
|